ML Attack Surface¶
You can include this MicroSim on your own page with the following iframe:
<iframe src="https://dmccreary.github.io/cybersecurity/sims/ml-attack-surface/main.html" height="432" width="100%" scrolling="no"></iframe>
About this MicroSim¶
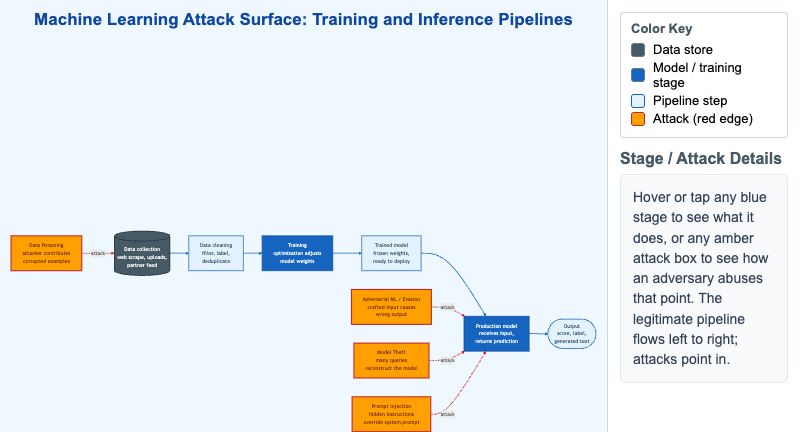
This diagram lays out the legitimate machine-learning pipeline left to right — data collection, cleaning, training, the frozen trained model, the production model, and its output — and then overlays the four attacks that target it as amber boxes connected by red edges. The point is that ML systems have a different attack surface than ordinary software: an adversary does not need to breach your servers if they can corrupt your data or craft your inputs.
Data Poisoning attacks the very first stage, where untrusted scrapes and uploads enter the corpus, so the model learns the wrong thing. The remaining three target the production model at inference time: Adversarial ML / Evasion crafts an input that produces a confident wrong answer; Model Theft reconstructs the model through many queries; and Prompt Injection hides instructions inside input so they override the system prompt. Hover over (or tap) any blue stage to read what it does, or any amber attack to read how it is abused. The split between a training-time attack and three inference-time attacks is the key takeaway: they require different defenses, and data cleaning alone does not stop poisoning.
Lesson Plan¶
Learning objective (Bloom: Understand). Students will identify the stages of the ML training and inference pipelines and match each ML-specific attack to the stage it targets, distinguishing training-time from inference-time threats.
Suggested classroom use. Project the diagram and have students trace one input from collection to output, then introduce each attack and ask the class to predict which stage it hits before revealing the answer. Close by asking which defenses (data provenance, input validation, rate limiting, prompt isolation) counter which attack.
Discussion questions:
- Why can thorough data cleaning reduce but never fully eliminate the risk of data poisoning? What assumption does cleaning make about upstream data?
- Three of the four attacks hit the production model. What does that tell you about where to concentrate inference-time monitoring and rate limiting?
- Prompt injection is often described as a trust-boundary failure rather than a model bug. What is the trust boundary, and why can the model not simply "ignore" injected instructions?
References¶
- Adversarial machine learning — Wikipedia
- Data poisoning — Wikipedia
- Prompt injection — Wikipedia
- OWASP Top 10 for Large Language Model Applications
Specification¶
The full specification below is extracted from Chapter 16: "Emerging Topics and Capstone".
Type: workflow-diagram
sim-id: ml-attack-surface
Library: Mermaid
Status: Specified
A horizontal flow diagram with two pipelines and labeled attack arrows pointing in.
Training pipeline (left half):
1. Data collection (web scrape, user uploads, partner feed)
2. -> Data cleaning (filter, label, deduplicate)
3. -> Training (optimization adjusts model weights)
4. -> Trained model (frozen weights, ready to deploy)
Inference pipeline (right half):
5. -> Production model (receives user input, returns prediction)
6. -> Output (score, label, generated text)
Attack arrows pointing INTO the pipeline:
- Red arrow at step 1 -> Data Poisoning (attacker contributes corrupted training examples)
- Red arrow at step 5 -> Adversarial ML / Model Evasion (crafted input causes wrong output)
- Red arrow at step 5 -> Model Theft (many queries reconstruct the model)
- Red arrow at step 5 -> Prompt Injection (instructions hidden in input override the system prompt)
Color: cybersecurity blue for legitimate pipeline, alert accent for attack arrows,
slate steel for data stores. Responsive: stacks vertically below 800px.
Implementation: Mermaid graph LR with custom classDefs for legitimate vs. attack edges.